
検索エンジンで自社のサイトを上位に表示させるためには、まずGoogleなどのシステムにサイトの存在を見つけてもらう必要があります。その役割を担うのが「クローラー」です。
この記事では、クローラーの種類や取得するファイルについて解説していきます。

AI検索時代にも通用するSEOの本質を学ぶ入門セミナーです。検索の仕組みや意図を整理し、コンテンツ、権威性、テクニカルSEOの観点から改善の考え方を解説。SEOの基本を学びたい方におすすめです。【参加費:無料】

クローラーとは
クローラーとは、インターネット上のWebサイトを巡回し、テキストや画像などのコンテンツ情報を収集する自動プログラムのことです。
GoogleやBingといった検索エンジンは、それぞれ独自のクローラーを持っています。クローラーがサイトを訪れて情報を持ち帰ることを「クロール」と呼び、このデータが整理されることで初めて検索結果に自分のサイトが表示されるようになります。

クローラーの種類
検索エンジンは、それぞれ独自のクローラーを持っています。主な検索エンジンのクローラー(bot)を一覧にまとめました。
Googlebot(Googleクローラー)
Google検索のクローラーは、Googlebotと呼ばれています。Googlebotは、数千台のマシンを効率的に動作させることで、毎日何十億ものページをクロールしているといわれています。
Bingbot
検索エンジンBingで使われるクローラーです。Bingでは、5種類のクローラーが稼働していて、一番よく利用されているクローラーが Bingbot です。
Yandex Bot / Baidu Spider
ロシア(Yandex)や中国(Baidu)で主に使われている検索エンジンのクローラーです。
その他のクローラー
ちなみに、検索エンジン以外にも次のようなクローラーがあり、Webサイトを巡回しています。
- Applebot:iPhoneのSiriやSpotlight検索で使用される情報を収集します。
- AhrefsBot / SemrushBot:競合サイトの分析ツールがデータを集めるために使用します。
AIクローラーの種類
2026年現在、検索エンジンだけでなく生成AIのためのクローラーも非常に重要な役割を持っています。AIがユーザーの質問に対して最新の情報を回答したり、検索結果にAIによる概要を表示したりするために、専用のプログラムがWebサイトの情報を収集しています。
主なAIクローラーの種類は以下の通りです。
- GPTBot:ChatGPTの学習データを集めるために使われます。
- OAI-SearchBot:OpenAIのAI検索機能などで最新情報を収集するクローラーです。
- Google-Extended:Googleの「Gemini」などのAIモデルが、サイトのコンテンツを学習に利用する際に管理されるユーザーエージェントです。
クローラーが取得するファイルの種類
- HTML:ページの文章構造
- CSS / JavaScript:デザインや動きのデータ
- 画像 / 動画:画像検索や動画検索の対象
- PDF / オフィス文書:WordやExcelなどのファイル
HTMLだけではなく、各種メディアファイルもクロールしていることに注目です。画像ファイルは画像検索、動画ファイルは動画検索で表示されますし、WordファイルやPDFファイルも検索結果に表示されます。
このうち、CSSとJavaScriptは検索結果に表示されませんが、Googleがコンテンツのランキングを評価する際に使われるため、クロールしています。
クローラーに見つけてもらう3つのルート
外部リンク
クローラーは、世界中にある Web ページを巡回し、すべてのリンク先をたどり続けています。外部サイトからのリンクが1つでもあれば、いずれはクローラーがサイトを見つけます。

巡回を依頼したURL
新しいサイトの場合は、 外部リンクが張られていません。そのようなときは、サイト URL を登録することで、クローラーに巡回を依頼できます。
Googleクローラーに巡回をリクエストするには、Googleサーチコンソールの URL検査ツールを使います。サーチコンソールで該当のURLを入力した後、[インデックス登録をリクエスト]ボタンをクリックします。
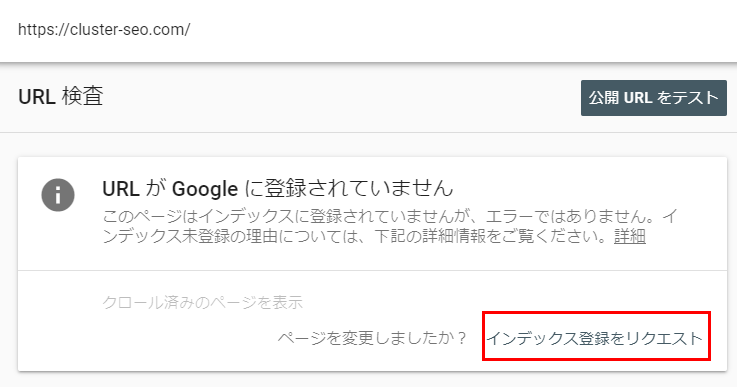
Bing も Web マスターツール を使うと、Bingbot に特定の URL への巡回を依頼できます。
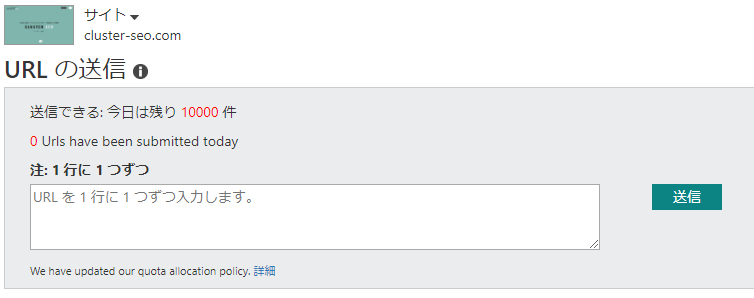
サイトマップ
クローラーは、「XMLサイトマップ」と呼ばれる、URL一覧を記述したファイルを読み取ります。サイトマップをサイトに設置すると、クローラーは効率的にサイトをクローリングできるようになります。

AI検索時代にも通用するSEOの本質を学ぶ入門セミナーです。検索の仕組みや意図を整理し、コンテンツ、権威性、テクニカルSEOの観点から改善の考え方を解説。SEOの基本を学びたい方におすすめです。【参加費:無料】
クローラーが巡回したページの確認
Googleクローラーがサイトを巡回して発見したページは、「site:」検索やGoogleサーチコンソールのカバレポートで確認できます。
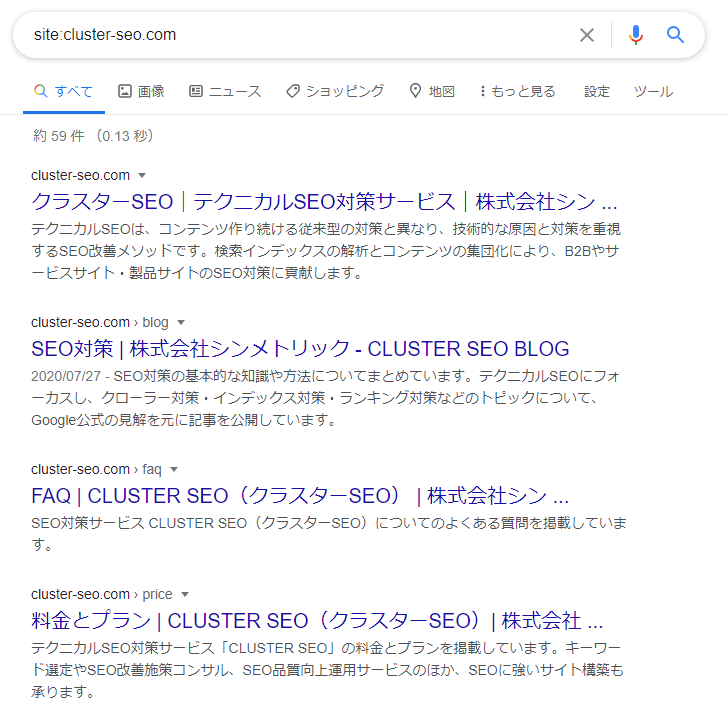
「site:」検索を使う
Google検索で、「site:ドメイン名」を入力して検索すると、特定ドメインのページ一覧が表示されます。
Googleサーチコンソールのページレポートを使う
次の手順で、Googleが巡回したページを確認できます。
- Googleサーチコンソールにログインします。
- [ページ]メニューをクリックします。
- 「インデックス登録済みのページ」や「未登録」の理由を確認します。
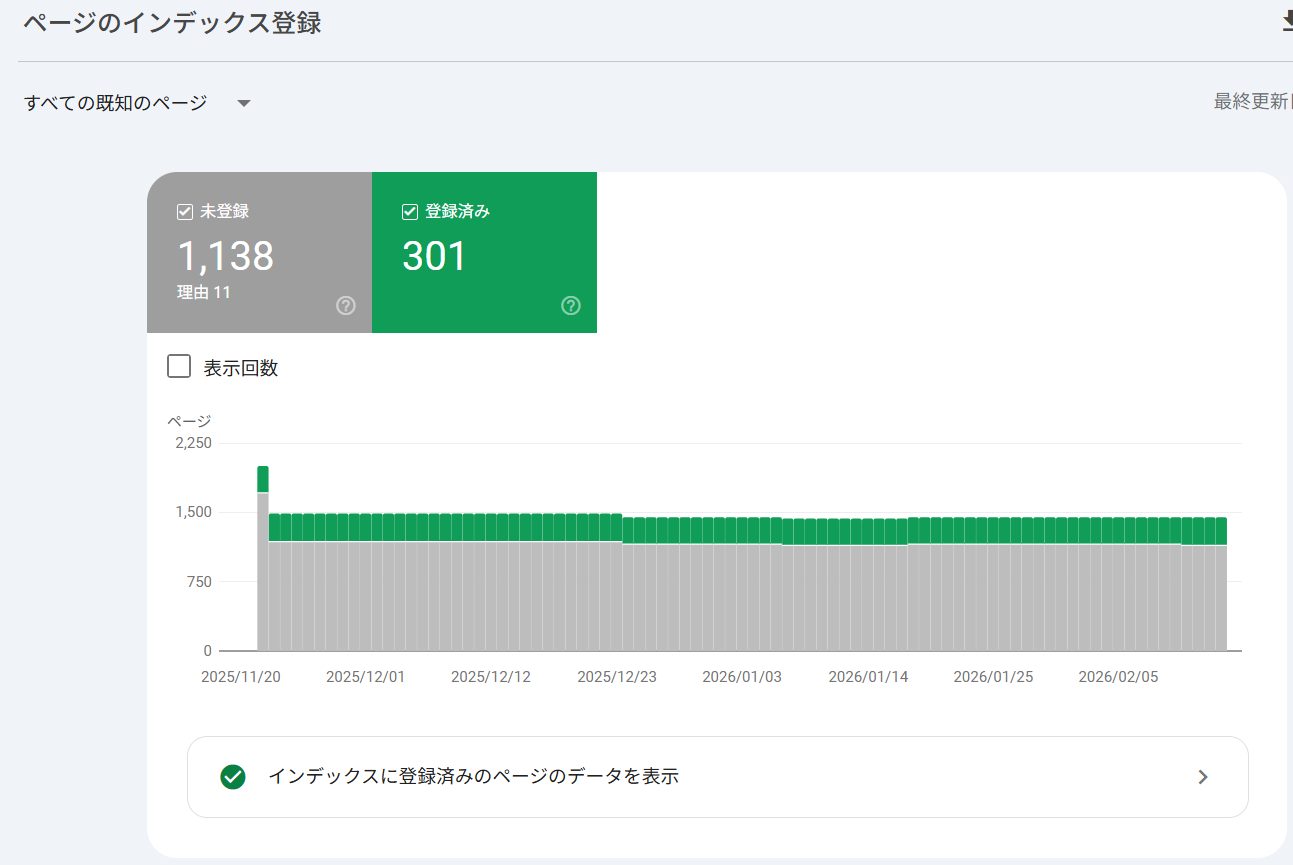
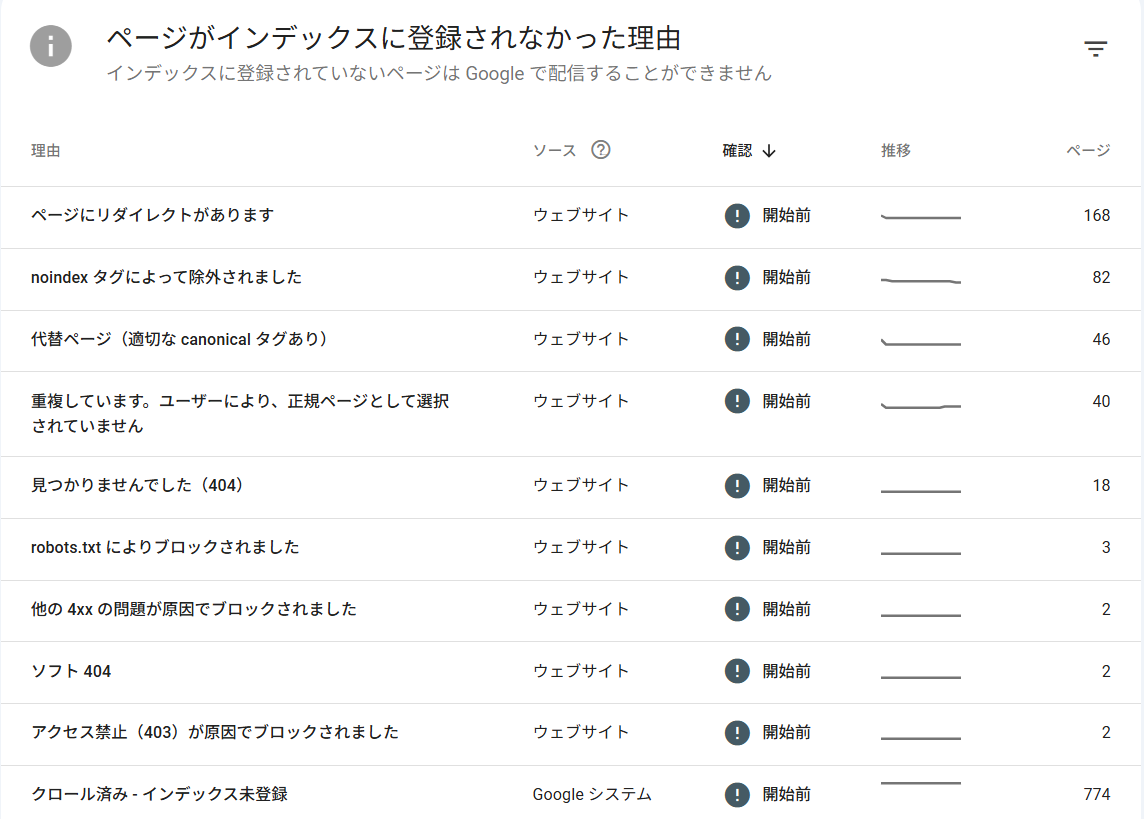
このように、クローラーがコンテンツを取得しても、すべてのページが検索インデックスに登録されるわけではありません。詳しくは、以下の記事を参照してください。

まとめ
この記事では、検索エンジンの仕組みである「クローラー」について、その種類や収集するファイル形式を解説しました。
続いて、クローラーの巡回の仕組みについては以下の記事をご覧ください。






