
robots.txtを正しく理解することで、サイトないのクロール状況をコントロールすることができます。
本記事では、robots.txtの基本構文からGoogleに正しく認識させるまでの一連の手順を解説します。

AI検索時代にも通用するSEOの本質を学ぶ入門セミナーです。検索の仕組みや意図を整理し、コンテンツ、権威性、テクニカルSEOの観点から改善の考え方を解説。SEOの基本を学びたい方におすすめです。【参加費:無料】

robots.txtの基本構文と正規表現
robots.txtは、以下の4つのディレクティブ(命令)を組み合わせて記述します。
User-agent
必須項目です。Allow/Disallowルールの対象とするクローラのUser-Agentを指定します。
User-agent:* と記述すると、すべてのクローラが対象となります。
※ほとんどのサイトでは、User-agent:*を記述するだけで十分です。
もし、特定のボットのみ指定する場合は User-agent:Googlebot のように記述します。
Disallow
アクセスを拒否するパスを指定する際に使用します。巡回を拒否するページの「URLパス」もしくは「URLパスの先頭部分」を指定して使用します。
例えば、以下のように使用します。
| 記述例 | 概要 |
|---|---|
| Disallow: / | すべてのURLを拒否します |
| Disallow: /mypage/ | /mypage/ ディレクトリ以下のURLを拒否し、それ以外を許可します |
| Disallow: /movie/clusterseo.mp4 | /movie/clusterseo.mp4 から始まるURLを拒否し、それ以外を許可します |
| Disallow: | 拒否設定なし |
Allow
Disallowで拒否したディレクトリの中で、例外的にアクセスを許可するパスを指定します。
こちらはDisallowとは逆で、巡回を許可するページの「URLパス」もしくは「URLパスの先頭部分」を指定します。
| 記述例 | 概要 |
|---|---|
| Disallow: /Allow: /public/ | 全URL拒否するが、/public/ディレクトリ以下だけは許可する ■許可されるURLパスの例/public//public/index.html/public/img/logo.svg ■拒否されるURLパスの例//index.html/news/ |
| Disallow: /video/Allow: /video/short.webm | /video/short.webmを除き、/video/ディレクトリは拒否する。それ以外は許可する。 ■許可されるURLパスの例//index.html/news//video/short.webm ■拒否されるURLパスの例/video//video/foo.webm |
Sitemap
省略可能な項目です。XMLサイトマップのフルURLを記述します。記述する際は、クローラにサイト構造を効率的に伝えるため、ファイルの末尾に記載するのが一般的です。
また、Sitemap はrobots.txt内に複数指定できます。ディレクトリごとにサイトマップが分かれている場合に使えます。
柔軟な指定を可能にする正規表現
複雑なURLパターンを制御するために、以下の記号(正規表現)が利用可能です。
- ワイルドカード(
*):0文字以上の任意の文字列を指します。- 例:
Disallow:/temp/*(temp配下の全ファイルを拒否)
※ワイルドカード(*)は、拡張子やクエリーパラメータを指定するときに便利です。
- 例:
| 記述例 | 概要 |
|---|---|
| Disallow: /*.mp4 | ファイル拡張子がmp4のURLをすべて拒否し、それ以外を許可します ■許可されるURLパスの例/clusterseo.webm/media/clusterseo.webm ■拒否されるURLパスの例/clusterseo.mp4/media/clusterseo.mp4 |
| Disallow: /search/*?from= | URLパスが /search/ から始まり、クエリー文字列が”from=”から始まるURLを拒否し、それ以外を許可します ■許可されるURLパスの例/search//search/?q=seo/search/item/search/item?q=seo ■拒否されるURLパスの例/search/?from=top/search/item?from=top |
- 行末一致(
$):URLの終わりを指定します。- 例:
Disallow:/*.php$(拡張子が.phpで終わるURLのみを拒否)
- 例:
| 記述例 | 概要 |
|---|---|
| Disallow: /campaign/$ | /campaign/ に完全に一致するURLのみを拒否し、それ以外を許可します ■許可されるURLパスの例//campaign/?from=top/campaign/index.html/campaign/img/ ■拒否されるURLパスの例/campaign/ |
robots.txtの記述例
よく使用されるパターンを紹介します。
サイト全体のクロールを許可する(デフォルト)
User-agent:*
Disallow:
サイト全体のクロールを拒否する
テスト環境などで、一時的に全ての巡回を止めたい場合に使用します。
User-agent:*
Disallow:/
特定のディレクトリやページを拒否する
ログインが必要なページや、検索エンジンに知らせる必要がない領域(例:/private/)を拒否します。
User-agent:*
Disallow:/private/
Disallow:/lp/test-page.html
特定のクエリパラメータ付きURLを拒否する
ソート順やフィルタリングなど、パラメータによって生成される重複コンテンツへの巡回を抑えます。
User-agent:*
Disallow:/*?sort=
Disallow:/*?filter=
robots.txt の反映確認
Google Search Consoleには、サイト上のrobots.txtがどのように読み込まれているかを確認できる「robots.txt レポート」が用意されています。アップロード後は、以下の手順でGoogleが正しくファイルを認識しているかを確認してください。
反映確認とレポートのチェック手順
- レポートにアクセスする
Google Search Consoleにログインし、左メニューの「設定」をクリックします。
- robots.txt レポートを開く
クロール セクションにある robots.txt の「レポートを開く」をクリックします。
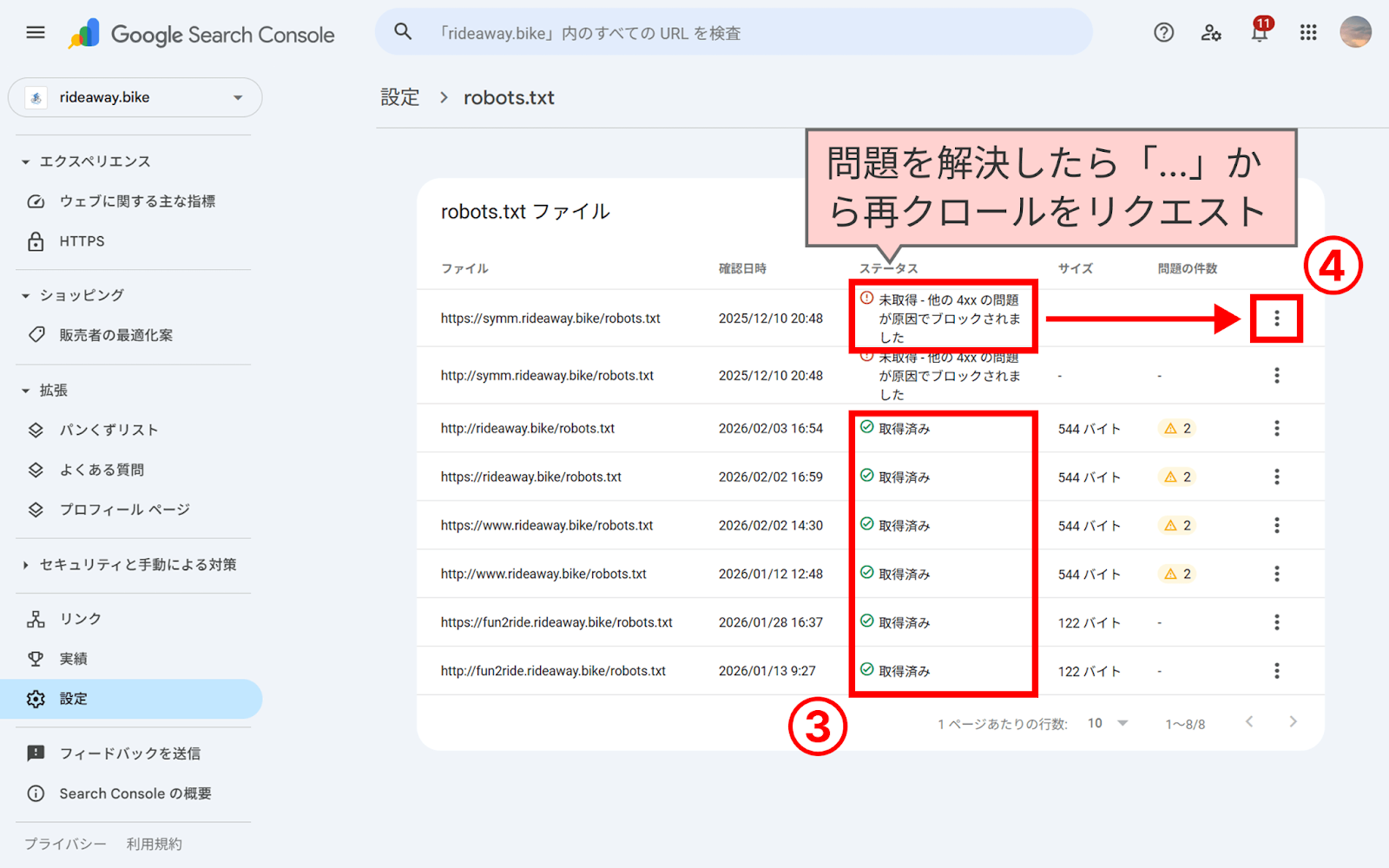
- ステータスをチェックする
- ステータス:「取得済み」となっているか確認します。
- 新しいバージョンの再読み込みをリクエストする
ファイルを更新した直後で、レポートに反映されていない場合は、該当のrobot.txtの「…」から「再クロールをリクエスト」をクリックしてGoogleに最新ファイルの読み込みを促します。
AI検索時代にも通用するSEOの本質を学ぶ入門セミナーです。検索の仕組みや意図を整理し、コンテンツ、権威性、テクニカルSEOの観点から改善の考え方を解説。SEOの基本を学びたい方におすすめです。【参加費:無料】
まとめ
robots.txtの設定は、単にファイルを置くだけでなく、意図した通りにクローラーが動作しているかを確認するまでがセットです。
記述を誤ると、意図せず重要なページが検索結果から消えてしまうリスクがあります。変更を加えた際は、必ずGoogleサーチコンソールの「robots.txt レポート」で確認しましょう。
robots.txtの役割とnoindexタグの違いは以下の記事で解説しています。






